이번 포스트에서는 이전에 데이터 베이스에서 추린 테이블과 컬럼을 바탕으로 통합 검색 기능을 구현해 볼 것이다.
MariaDB 드라이버 추가하기
MariaDB에 연결하기 위해서는 mariaDB 드라이버를 추가해야 한다. 하단의 경로에 접속해서 다운로드 버튼을 클릭한다.
https://mariadb.com/downloads/connectors/connectors-data-access/java8-connector/

다운로드가 완료된 jar 파일은 C:\solr\server\solr-webapp\webapp\WEB-INF\lib 에 추가한다.
Solr와 연동할 설정 파일 연결하기
이전에 코어를 생성했다면, C:\solr\server\solr 폴더 경로에 생성한 코어 이름으로 폴더가 존재할 것이다.
해당 폴더 밑에 있는 conf 폴더 안의 solrconfig.xml 파일을 수정해서 DIH 설정 파일을 지정해주어야 한다.
solrconfig.xml을 열고 맨 아래 </config> 앞쪽 부분에 해당 코드를 넣고 저장한다.
<lib dir="${solr.install.dir:../../../..}/dist/" regex="solr-dataimporthandler-.*\.jar" />
<requestHandler name="/dataimport" class="org.apache.solr.handler.dataimport.DataImportHandler">
<lst name="defaults">
<str name="config">db-data-config.xml</str>
</lst>
</requestHandler>DIH 설정 파일 만들기
DIH(Data Import Handler)는 Apache Solr의 한 기능으로, 다양한 데이터 소스로부터 데이터를 가져와서 Solr 인덱스에 쉽게 색인할 수 있도록 도와주는 프레임워크이다.
DIH는 데이터베이스, CSV 파일, XML 파일, 이메일 등 다양한 형식의 데이터 소스를 지원하며, 이를 통해 대량의 데이터를 Solr 인덱스로 효율적으로 가져올 수 있다.
이전에 설정 파일을 연결했다면, 이제는 C:\solr\server\solr\shiba_holic\conf 폴더에 db-data.config.xml 파일을 만들어 데이터 소스와 데이터를 가져오는 방법을 정의해야 한다. 정의하는 방법은 아래와 같다.
<?xml version="1.0" encoding="UTF-8" ?>
<dataConfig>
<dataSource type="JdbcDataSource" driver="org.mariadb.jdbc.Driver" url="jdbc:mariadb://localhost:3306/<데이터베이스 이름>" user="<아이디>" password="<비밀번호>" />
<document>
<entity name="<엔티티 이름(자유롭게)>" query="SELECT <조회할 컬럼 목록> FROM <조회할 쿼리 테이블> ">
<field column="<조회할 컬럼 이름>" name="<Solr에서 사용할 컬럼 이름>"/>
</entity>
</document>
</dataConfig>
1. dataSource 태그 url에 데이터베이스 정보를 입력한다.
2. entity 태그 query에 조회할 테이블과 컬럼 목록을 입력한다.
3. entity 태그에 solr에서 해당 테이블에서 추출한 데이터 세트를 구분할 엔티티 이름을 자유롭게 추가한다.
4. field 태그 column에는 query에서 조회한 컬럼 이름을 적고, name에는 데이터 세트에서 구분할 컬럼 이름을 작성한다.
테스트를 위해 작성한 예시는 다음과 같다.
테이블 이름 = tb_post
추출할 컬럼 이름 = title, content

테이블 이름 = tb_pet_owner
추출할 컬럼 이름 = email, name

통합 검색에서 키워드를 검색하면 tb_post 테이블의 제목, 내용 중 해당하는 게 있거나, tb_pet_owner의 이메일과 이름 중에 일치하는 게 있는지 확인한 뒤 관련 내용을 반환하게 구현할 것이다.
해당 내용을 바탕으로 작성한 설정 파일은 아래와 같다.
<?xml version="1.0" encoding="UTF-8" ?>
<dataConfig>
<dataSource driver="org.mariadb.jdbc.Driver" url="jdbc:mariadb://localhost:3306/blog?autoReconnect=true" user="" password="" />
<document>
<entity name="post" query="SELECT 'post' as category, seq, title, content FROM tb_post ">
<field column="category" name="category"/>
<field column="seq" name="pk"/>
<field column="title" name="search" />
<field column="content" name="search" />
</entity>
<entity name="pet_owner" query="SELECT 'owner' as category, seq, email, name FROM tb_pet_owner ">
<field column="category" name="category"/>
<field column="seq" name="pk"/>
<field column="email" name="search" />
<field column="name" name="search" />
</entity>
</document>
</dataConfig>
1. 검색된 데이터의 카테고리를 구분하기 위해 별도의 컬럼 이름을 추가했다.
2. 테이블의 pk 값은 데이터 세트의 pk라는 이름으로 정의하였다.
3. 검색 대상 값은 'search' 라는 컬럼 이름으로 조회할 것이므로 search로 통일하였다.
Schema 작성하기
DIH 설정 파일에 작성한 필드들의 타입과 옵션을 managed-schema에 정의해야 한다.
managed-schema.xml 파일은 Apache Solr에서 사용하는 스키마 파일의 한 형태로, Solr 인스턴스의 스키마를 정의한다. 이 파일 내에서 <field> 태그는 문서의 필드와 그 특성을 정의하는 데 사용된다. 각 필드는 여러 속성을 가질 수 있다.
C:\solr\server\solr\shiba_holic\conf 폴더에 있는 managed-schema.xml을 열어서 <field name="id"를 검색한 뒤, 아래에 다음과 같이 추가한다.
<field name="category" type="string" indexed="false" stored="true" required="true" multiValued="false" />
<field name="pk" type="string" indexed="false" stored="true" required="true" multiValued="false" />
<field name="search" type="text_ko" indexed="true" stored="true" required="false" multiValued="true" />
필드에 정의한 속성들의 특징들은 다음과 같다.
type
필드 타입은 필드에 저장될 데이터의 종류와 그 데이터가 어떻게 처리될지를 결정한다. 예를 들어, 문자열(string), 정수(integer), 텍스트(text) 등이 있으며, 각 타입은 특정한 분석기(analyzer)와 토크나이저(tokenizer)를 사용하여 데이터를 인덱싱 하고 검색할 수 있도록 한다.
indexed
필드가 인덱싱되어야 하는지 여부를 결정한다. indexed="true"로 설정하면, 해당 필드는 검색 쿼리에서 사용될 수 있으며, Solr는 이 필드를 인덱스에 포함시킨다. 인덱싱 된 필드는 검색 가능하며, 필터링, 정렬, 퍼싯(faceting) 등에 사용될 수 있다.
stored
필드의 원본 데이터가 저장되어야 하는지 여부를 결정한다. stored="true"로 설정하면, Solr는 원본 데이터를 저장하고, 검색 결과를 통해 해당 데이터를 검색할 수 있다. 저장된 필드는 검색 결과에서 원본 데이터를 보여주는 데 사용된다.
required
필드가 필수적인지 여부를 결정한다. required="true"로 설정하면, 해당 필드는 문서를 인덱싱할 때 반드시 포함되어야 한다. 필수 필드가 없는 문서는 인덱싱 과정에서 오류를 발생시킬 수 있다.
multivalued
필드가 여러 값을 가질 수 있는지 여부를 결정한다. multivalued="true"로 설정하면, 해당 필드는 하나의 문서에 대해 여러 개의 값을 가질 수 있다.
text_ko 타입
text_ko 필드 타입은 한국어 텍스트를 위한 필드 타입이다. 이 필드 타입은 한국어 텍스트의 특성을 고려하여 토크나이징(tokenizing)과 분석(analysis)을 수행하기 위해 특별히 설정된 필드 타입이다.
text_ko 필드 타입은 한국어의 어절, 형태소 분석, 동의어 처리 등을 지원하기 위해 한국어를 처리할 수 있는 분석기(analyzer)와 토크나이저(tokenizer)를 사용한다.
검색할 내용에 한국어가 포함될 가능성이 있다면, 해당 타입을 사용해야 한다.
해당 내용은 managed-schema 파일에서 찾아볼 수 있다.

DATA IMPORT 하기
해당 설정까지 완료했다면, solr를 재시작한다. 재시작 명령어는 다음과 같다.
solr restart -p 8983
그다음 solr Admin 화면에서 코어에 접근하면 하단에 Data Import라는 메뉴를 확인할 수 있다.
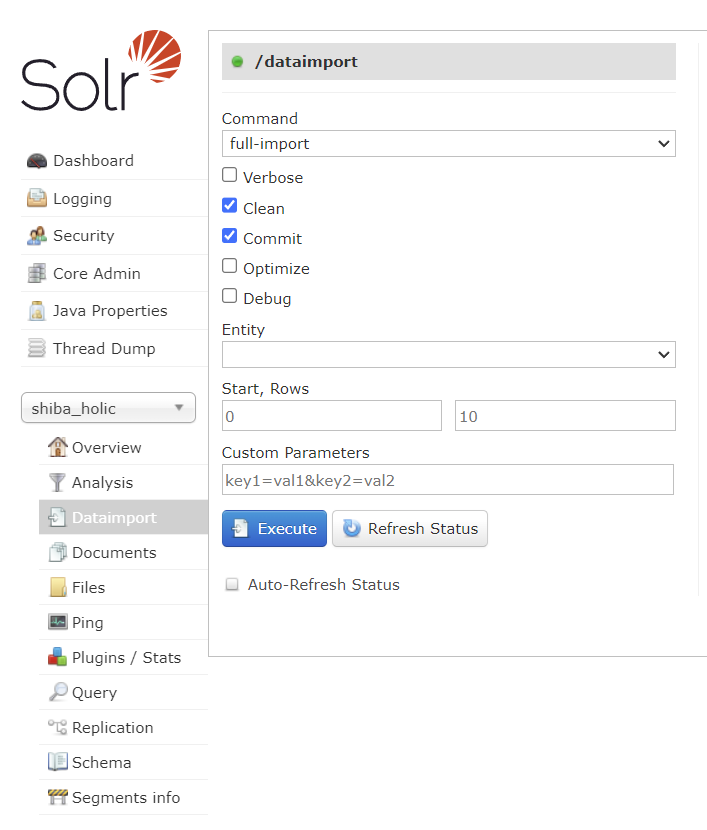
해당 메뉴에 들어가서 clean, Commit 버튼을 클릭하고 Execute를 클릭한다. 그러면 우측에 Indexing since 표시가 나오는데, 자동으로 변경되지는 않으므로, Execute 옆 Refresh Status를 클릭해서 새로고침 해준다.

데이터를 정상적으로 가져왔다면 하단의 메시지 처럼 Added/Updated 값이 데이터 개수만큼 표시될 것이다.

데이터 검색하기
코어 메뉴 중 'Query'로 이동해서 Execute Query 버튼을 클릭하면, 하단의 이미지처럼 우측에 예상했던 데이터 세트가 출력된다.
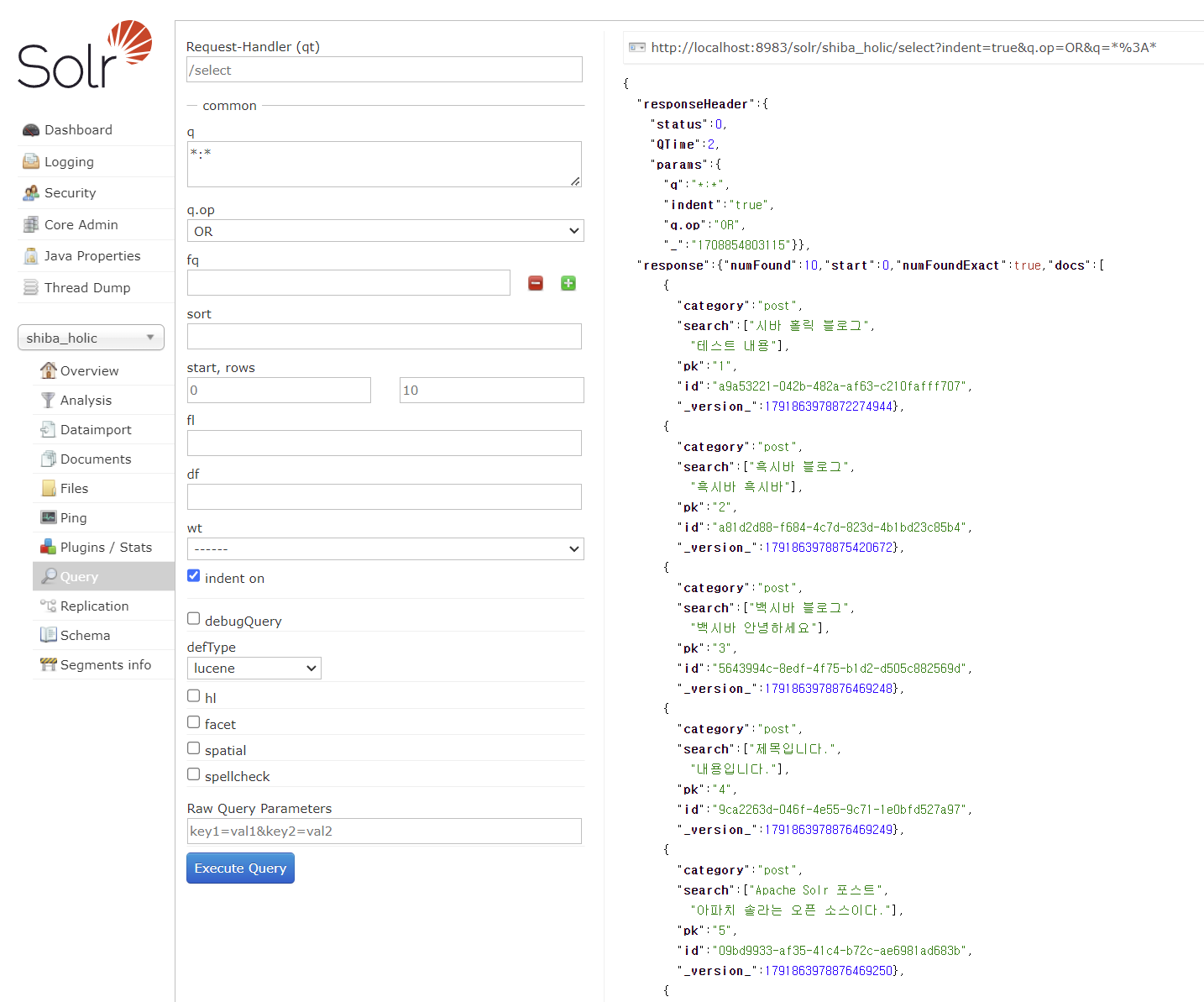
q 파라미터에 '필드:값' 형식으로 입력하면 특정 키워드 조회가 가능하다. 만약 '시바'라는 키워드를 검색하고 싶다면 search:시바라고 입력하면 된다.

q 파라미터는 검색어 또는 검색 표현식을 지정하는 데 사용된다. 이 파라미터는 사용자가 입력한 검색어를 Solr 검색 엔진에 전달하며, Solr의 검색 핸들러는 이를 해석하여 적절한 검색 결과를 반환한다.
여러 조건을 조합할 때는 AND, OR, NOT (또는 &&, ||, -) 연산자를 사용할 수 있으며, 별표(*)를 사용해서 부분 일치 검색을 수행한다.
시바와 홀릭이라는 키워드를 동시에 포함하고 있는 데이터를 검색하고 싶으면 아래 이미지와 같이 search:*시바* AND *홀릭* 이런 식으로 사용할 수 있다.

solr는 기본적으로 API 검색을 지원하기 때문에 다음과 같이 API로 데이터를 호출해도 동일한 결과가 출력된다.
http://localhost:8983/solr/shiba_holic/select?indent=true&q.op=OR&q=search:*시바* AND search:*홀릭*&wt=json
이것으로 Apache Solr를 활용하여 MariaDB 통합 검색 기능 구현을 완료했다.
Solr는 해당 기능 외에도 다양한 많은 기능을 제공하고 있다. 풍부한 기능과 확장성을 갖춘 Solr은 대용량 데이터의 효율적인 검색 및 분석을 위한 강력한 도구이므로, 잘 활용해서 유용한 비즈니스 서비스를 만들어 보도록 하자.
REFERENCE
'OpenSource > Apache Solr' 카테고리의 다른 글
| Apache Solr를 활용하여 MariaDB 통합 검색 기능 구현하기 (1) (0) | 2024.02.24 |
|---|

댓글